Un hold-up à 10 millions de tokens
C’est l’histoire d’un hold up à 10 millions, un grand casse de comm.
Si vous avez bien suivi LinkedIn, jeudi dernier Google a dévoilé Gemini 1.5 leur dernier LLM, suivi quelques heures après par OpenAI dévoilant Sora, un modèle text-to-video au rendu hallucinant et rêveur (je vous laisse regarder la désormais célèbre vidéo de la chaise de sable qui s’enfuit). S’en est suivi de milliers de posts sur ces fameuses vidéos.
Dommage pour Google car c’est sur SES vidéos de démonstration de Gemini 1.5 que vous auriez dû vous extasier / enthousiasmer / cacher.
Pourquoi ?
Gemini 1.5 est un modèle multimodal qui offre un contexte d’entrée à 1M de tokens, possiblement 10M, et affichant des performances équivalentes à Gemini 1.0 ultra (équivalent GPT4). Un tel contexte représente des prompts équivalents à 1h de vidéo, 30k lignes de codes ou un document de 1400 pages.
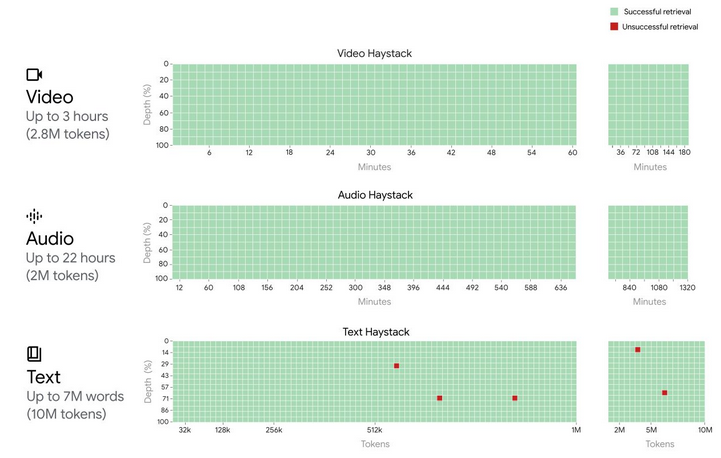
Le plus impressionnant, c’est sa performance : 99.7% d’accuracy. C’est-à-dire que le modèle se “souvient” du moindre détail qui lui a été fourni en entrée (regardez bien l’image pour 10M de tokens !)
Ce que ça implique et les perspectives
Une partie des systèmes de RAG que nous (nous collectif) avons créé dans le sang et les larmes ces derniers mois va être concurrencé par 1 (UN) appel à une API.
Pour les profanes : un RAG permet de fournir à un LLM du contenu pour formaliser une réponse à une question. Ceci permet de travailler sur de la connaissance inconnue du modèle, comme une procédure interne.
Prenons un exemple concret (et simplifions) : votre procédure interne de 1000 pages est découpée en plusieurs blocs de texte ou d’image, chaque bloc est transformé et stocké sur une base de données. Quand une demande arrive, on va chercher dans ces blocs les éléments qui peuvent fournir une réponse pour ensuite les faire formaliser par un LLM.
Avec Gemini 1.5, vous mettez juste le contenu de votre document dans le prompt et c’est réglé. Un appel API coûtera certes peut-être 5€ dans un premier temps, mais offrira certainement de meilleurs résultats vu la performance annoncée.
Applications concrètes
Imaginez, vous avez un ensemble de documentations techniques et fonctionnelles, vous voulez connaître l’impact du changement d’un seul paramètre sur l’ensemble : c’est fait en 1 appel à une API. Et je ne parle même pas du potentiel multimodal !
Imaginez une IA spécialisée en médecine avec un grand contexte comme celui-ci. En moins d’une minute, un dossier médical, l’historique des soins, les traitements, les radios, les IRMs peuvent être analysés par un système qui n’est pas soumis à des aléas biologiques comme la fatigue, la concentration, les soucis personnels etc. Ce n’est plus de la science fiction, c’est dans les 2 prochaines années maximum.
Je parle de médecine, mais l’application aux secteurs juridique, conseil, RH va être démentielle (grands boucliers d’égos à prévoir).
Conclusion
Je reste sur ma ligne : always bet on Google.